
















For data scientists and machine learning engineers, version controlling data is just as important as version controlling code. As models become more complex and datasets grow larger over time, being able to reliably track changes, collaborate with teammates, and reproduce experiments becomes critical.
This is where Data Version Control (DVC) comes in. DVC is an open-source tool designed specifically for data science projects that integrates directly with Git to provide robust data and model versioning functionality. With DVC, you can efficiently track changes to datasets, manage different model versions, and seamlessly collaborate with others - all while keeping data and code perfectly synced.
In this guide, we'll provide an in-depth explanation of how to get started with DVC, demonstrate how to do data version control in your own projects, and explore some advanced DVC features. By the end, you'll have a solid understanding of how to leverage DVC and take your data science workflow to the next level.
What is Data Version Control?
Before diving into DVC, it's important to understand the core principles behind data version control and why it's such a useful tool for data scientists.
Data version control treats datasets and machine learning models as first-class citizens in a project alongside source code. Just as software engineers use Git to collaborate and track changes to code over time, data scientists can use DVC in data science to accomplish the same goals for data-related assets.
This provides some key benefits:
- Reproducibility: Being able to tie models and experiments to specific dataset versions ensures results can be recreated reliably down the line.
- Collaboration: Team members can work simultaneously on code and data without conflicting with each other.
- Auditability: The full history of changes to data is recorded, making it possible to see what influenced model performance over many iterations.
- Portability: Datasets and models can be shared across various environments while maintaining references between versions.
- Data integrity: Integrity checks detect unintended alterations to datasets during processing to avoid bugs.
So, in summary, data version control brings the same discipline, tracking, and collaboration abilities that version control provides for code to the data side of machine learning projects. DVC streamlines this workflow and integrates it directly with the popular Git version control system.
Getting Started with DVC
Now that we understand the motivations behind data versioning, let's walk through setting up DVC on your local machine. These steps will get you up and running to start tracking datasets.
-
1.Install DVC
DVC works on Linux, macOS, and Windows. To install, simply run:
pip install dvc
-
2.Initialize a Repo
Navigate to an existing or new project directory with Git initialization. To start versioning with DVC, run:
dvc init
This will configure DVC to cooperate with the local Git repo.
-
3.Add Your First Dataset
If your project includes sample data in a `data/` folder, add it to DVC tracking:
dvc add data/
DVC will analyze the data and record a checksum for each file in a `.dvc` metadata file alongside the data.
-
4.Commit to Git
Add the new DVC files and commit the setup. This will preserve references between Git commits and DVC data versions:
git add .gitignore data/*.dvc
git commit -m "Initialize DVC"And with those few basic steps you've integrated data versioning into your workflow! DVC is now set up to keep perfect sync between your code and data changes under Git.
Tracking File Changes with DVC
Once DVC is initialized, tracking further changes to datasets is straightforward. Here are the basic steps:
-
1.Modify a Dataset
Make an update to data, like adding new rows to a CSV.
-
2.Run `dvc status`
This will detect any changes to tracked files compared to the last commit.
-
3.`dvc add` Updated Files
Re-add changed files to stage the updates for commit.
-
4.Commit with `dvc commit`
This commits changes to DVC and records new checksums.
-
5.Commit to Git
Add generated `.dvc` files and commit as usual to synchronized versioning.
Let's break this down with an example. Assume we have a `data.csv` file being tracked with 100 rows initially. After adding 10 more rows:
# Check the current status of tracked files
dvc status
# Output:
# data.csv - modified# Stage the updated file with DVC
dvc add data.csv# Save the updated data version with DVC
dvc commit -m "Added 10 rows to data"# Add DVC tracking information to Git
git add data.csv.dvc# Commit the new version in Git
git commit -m "Updated data version with 10 more rows"Now both Git and DVC capture the new 110 row version of `data.csv` so it can be reproduced from any commit.
As a data science project grows, DVC will seamlessly scale to manage increasing volumes of versioned files with these same simple commands.
Linking Remote Storage for Large Data
A common challenge for version controlling large datasets is that storing every variant directly in a Git repository can become prohibitively slow and bloated over time. To address this, DVC integrates with popular remote storage services to optimize large file handling.
The main remote options supported are:
- AWS S3 - Interface with S3 buckets for scalable object storage.
- Google Cloud Storage - Equivalent to S3 on Google Cloud Platform.
- Azure Blob Storage - Microsoft's object storage solution.
- SSH/FTP servers - Leverage existing remote server infrastructure.
- Local filesystem - Useful for initial PoC before using cloud storage.
To get started, generate credentials for your preferred service according to its documentation. Then use `dvc remote` to configure DVC to use it:
dvc remote add -d storage s3://mybucket
This tells DVC to store actual data in S3 instead of the local Git repo. From now on, `dvc push` will sync data with the remote, while `dvc pull` retrieves it.
Behind the scenes, DVC manages checksum-based deduplication so only file changes take up extra space. As a project grows to terabytes of data, this remote integration is critical to make effective use of available storage resources.
Managing Model Versions with DVC
In addition to versioning raw datasets, DVC is also well-suited for tracking machine learning models over time. Each model can be treated as an artifact to version alongside corresponding dataset snapshots.
For example, consider a project that generates weekly predictions by re-training a model on new data each period. We may want to:
- Archive old model files
- Detect unintended changes to models
- Roll back predictions to prior model versions
- Audit model performance over time
To manage this scenario with DVC:
- Place model files in a `models/` directory.
-
Add to tracking after each training run:
dvc add models/week1_model.pkl
-
Commit with descriptive messages:
dvc commit -m "Week 1 model"
Now old model files will be preserved just like other DVC-tracked assets. We can also query metrics for each version. Combining the Git+DVC approach brings full reproducibility to both models and data over the long run.
Incorporating DVC in Pipelines
To achieve end-to-end data versioning for an entire workflow, DVC should be incorporated directly into automated training pipelines. This is easily done using a simple DVC configuration file called `dvc.yaml`.
A sample `dvc.yaml` may include:
stages:
- name: preprocess
cmd: python preprocess.py
deps:
- data/raw_data.csv
- config.yaml
outs:
- data/preprocessed.pkl
- name: train
cmd: python train.py
deps:
- data/preprocessed.pkl
outs:
- models/202301_model.pkl
Now when `dvc repro` is run, it will execute the steps while tracking all files as DVC dependencies. Output artifacts are automatically added to versioning.
Taking the `dvc.yaml` approach streamlines data versioned operation of the full ML life cycle from data ingestion to model deployment. Team members can collaborate directly within the DVC framework to manage all project assets together.
Branching and Merging with DVC
When using DVC, you can create branches in the same way you do in Git. Branches allow you to try different changes or experiments without affecting the main branch of work. With DVC, when you create a new branch, it doesn't copy all the data files. It only changes which metadata files it will read from when running commands like 'dvc pull' or 'dvc repro'.
This means new branches are very lightweight because they don't duplicate large dataset files. You can freely switch between branches to work on different ideas or bug fixes. DVC will know how to find the right dataset versions for each branch based on the metadata.
If you make changes to datasets in a branch, DVC will update the metadata to track these changes. When you want to combine branches, DVC allows you to merge branches together just like Git. During a merge, it will combine the metadata and datasets, so you have a single consistent version again across the whole project. This helps teams collaboratively develop models with experimental branches, while keeping a stable main branch of work.
Here are the steps for branching workflow with DVC:
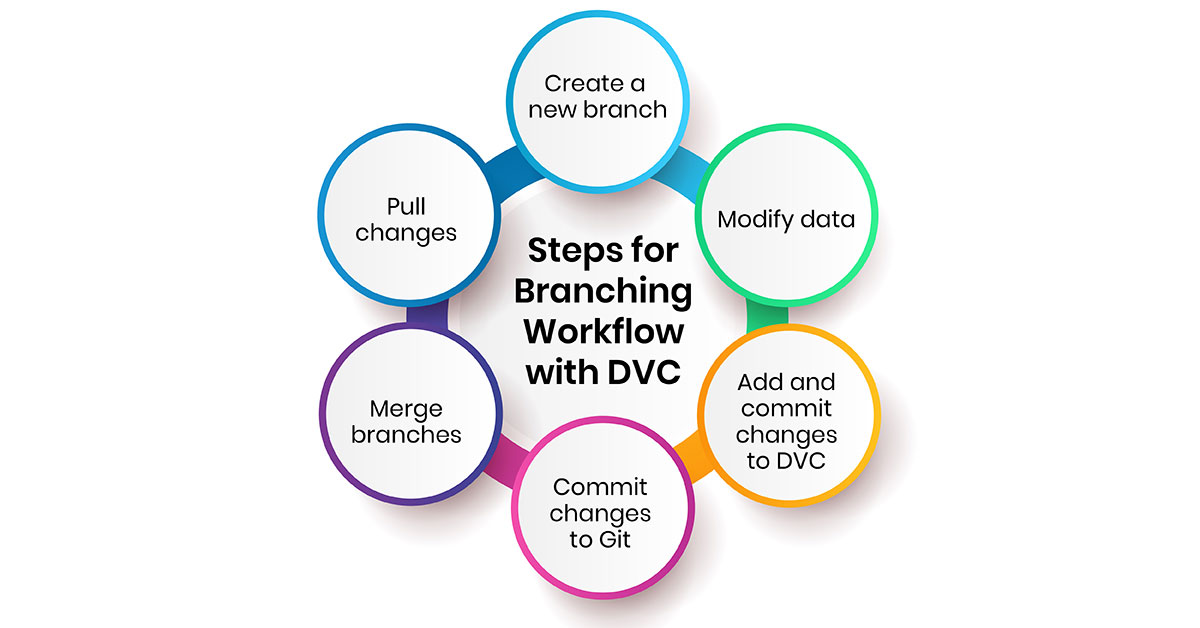
- 1.Create a new branch: Use the git checkout command to create and switch to a new branch for experimenting, e.g. git checkout -b new-branch.
- 2.Modify data: Make changes to the dataset files being tracked by DVC in the new branch.
- 3.Add and commit changes to DVC: Run dvc add to add any new dataset files. Then dvc commits to commit the changes.
- 4.Commit changes to Git: Add and commit the changed .dvc files to the new branch in Git with git add .dvc and git commit.
- 5.Merge branches: If the experiments were successful, merge the new branch back into main/master with git merge new-branch. If not, the changes remain isolated in the branch.
- 6.Pull changes: To view the merged changes, checkout main/master and run dvc pull to retrieve the updated dataset files.
This allows experimenting freely with different versions or modifications to datasets in separate branches before deciding whether to merge changes back, maintaining a clean and organized workflow with DVC.
Versioning Metrics and Model Evaluation
When training machine learning models, it is important to track various metrics at each step to compare performance and choose the best models. DVC can help version metrics along with code and data to allow comparing metrics for different experiments and reproducibility.
Some key metrics that are commonly evaluated and tracked include:
- Accuracy - Measures what percentage of predictions were correctly classified.
- Precision - Measures what percentage of positive predictions were actual positives.
- Recall - Measures what percentage of actual positive cases were predicted positive.
- F1 Score - Harmonic mean of precision and recall providing a balanced measure.
- ROC AUC - Area under the receiver operating characteristic curve measuring model's ability to distinguish classes.
DVC supports tracking metrics defined as params files containing metrics for each run. For example, a params.yaml file may contain:
params:
- run_1:
accuracy: 0.9
precision: 0.8
recall: 0.85
- run_2:
accuracy: 0.89
precision: 0.82
recall: 0.9
This allows monitoring changes in metrics over time. DVC also supports visualizing metrics plots as discussed later.
When training models, it is important to evaluate both training and validation/test sets to check for overfitting. The evaluate.py file below calculates and logs metrics on both sets using sklearn:
from sklearn.metrics import classification_report
import logging
def evaluate(model, x_train, y_train, x_test, y_test):
train_preds = model.predict(x_train)
test_preds = model.predict(x_test)
train_report = classification_report(y_train, train_preds)
test_report = classification_report(y_test, test_preds)
logging.info("Train metrics: ")
logging.info(train_report)
logging.info("Test metrics: ")
logging.info(test_report)
DVC allows versioning such evaluation code and metrics together with experiments to track model performance over iterations of the hyperparameter tuning process.
Visualizing and Comparing Metrics with DVC Plots
DVC provides out-of-the-box functionality to easily visualize metrics from params files on interactive plots for comparing experiments. This helps analyze changes in model performance visually.
To generate plots, run the dvc plot command:
dvc plot params.yaml --output plots/metrics.html
This will create an HTML file with an interactive bokeh plot containing all metrics from the params file for each run. Lines, bars and markers allow visual inspection of changes.
Filters can be applied on the plots to focus only on particular metrics, or a subset of runs using the --filter option. For example:
dvc plot params.yaml --filter "run_1, run_2" --filter-metric "accuracy,precision"
This will plot only accuracy and precision for run 1 and 2.
Multiple params files can also be compared by specifying them all with a dvc plot. Color coding helps distinguish between files.
The plots are interactive - users can hover over points, click legends to toggle series etc. They serve as a powerful review tool during iterations to visually analyze how different hyperparameters or techniques impact metrics.
Managing Experimentation and Hyperparameter Tuning with DVC Experiments
DVC experiments provide a structured way to manage hyperparameter tuning runs and link them with code, data and metrics to track results over iterations.
An experiment is defined in a YAML file specifying parameters, their values, and the command to execute. For example:
name: Neural Network Experiment
command: python train.py
params:
- learning_rate: 0.1
num_epochs: 10
- learning_rate: 0.01
num_epochs: 50
- learning_rate: 0.001
num_epochs: 100
This defines 3 runs with different hyperparameters. DVC tracks outputs of each run like models, logs, metrics etc. in separate dirs named after the run params hash.
To recreate any experiment run:
dvc repro <exp_dir>/<run_hash>
Plots of results across runs can also be generated:
dvc exp view <exp_dir>
This structured approach improves reproducibility and transparency of the tuning process. New runs can be added over time, compared with historic runs for better hyperparameter selection.
CI/CD Integration and Automation
DVC integrates smoothly with continuous integration (CI) and continuous delivery (CD) workflows for automated testing and deployment.
On every commit, a CI pipeline can be automatically triggered to:
- Checkout code using dvc pull
- Install dependencies
- Run model training/evaluation scripts
- Collect and validate metrics
- Run tests
- Package and deploy artifacts
This allows testing changes and tracking model performance after every code/data update. Services like Gitlab CI, Github Actions, Jenkins, Azure DevOps etc. all support DVC out-of-box.
For deployment, DVC push can be used to upload latest artifacts to remote storage like S3. Then a CD job triggers model import/update.
Tools like DVC-dashboard also allow monitoring runs, commits, dependency changes in real-time for visibility.
With DVC, teams get automated testing feedback to ensure stable, deployment-ready code after every change while continuously improving model quality through hyperparameter tuning experiments and iterations.
Advanced Data Management: Working with Data Caches
When datasets become too large to push/pull every time, DVC employs data caching. It avoids refetching unchanged data, improving efficiency while retaining full reproducibility.
The basic workflow is:
- Add datasets to DVC
- Run dvc push to upload once
- Subsequent runs use the local cache by default
- Trigger dvc pull only if data changed upstream
The cache location can be specified during dvc init. Files checksums are compared to verify no changes.
For very large datasets, partial caching allows caching only changed parts. This further optimizes storage usage and network traffic.
Tools like DVC-DASH provide visibility into cached/uncached files for any commit. This insight aids debugging and ensures researchers/developers don't accidentally use outdated data.
Overall, caching improves data handling performance without sacrificing reproducibility even for petabytes of data. Combined with DVC's immutable storage, it eases data management challenges at scale.
Handling Complex Pipelines with Multi-Stage DVC Pipelines
For complex machine learning pipelines with multiple data processing/transformation stages before training, DVC supports multi-stage pipelines.
Each stage can have its own code, data and metrics tracked as a separate DVC task. Tasks define dependencies, input/output artifacts to reconstruct any stage from source.
For example, a typical NLP pipeline may have:
- Data Preprocessing (task 1)
- TF-IDF Vectorization (task 2 depends on task 1)
Training (task 3 depends on tasks 1, 2)
The dvc.yaml config defines this topology:
tasks:
task1:
cmd: python preprocess.py
deps: [data/]
outs: [preprocessed_data.pkl]
task2:
cmd: python tfidf.py
deps: [task1/preprocessed_data.pkl]
outs: [vectors.pkl]task3:
cmd: python train.py
deps: [task1/preprocessed_data.pkl, task2/vectors.pkl]
metrics: metrics.json
Now running dvc repro on any task replays the entire pipeline from that point onward with correct data/artifacts. This brings robustness to complex pipelines.
Advanced patterns like partial runs, interactive exploration of intermediate results are also supported for streamlining research. DVC handles intricate orchestration under the hood.
Conclusion
In conclusion, data version control is an essential tool for data scientists and machine learning engineers working with complex datasets and models. As data volumes continue growing rapidly, proper versioning of data using a tool like DVC integrated with Git provides an effective way to track changes, ensure reproducibility of experiments, and facilitate seamless collaboration.
Adopting best practices of data version control from the start of any data science project provides numerous benefits like transparency, productivity boost, and reliability throughout the entire data pipeline. DVC emerges as a powerful solution that helps maximize insights from data by addressing challenges of data management, which is increasingly becoming a barrier to progress.













