

















Apache Airflow is one of the most popular tools used by data engineers to schedule and monitor their data pipelines. In this comprehensive guide, we will explore how Apache Airflow helps data engineers streamline their daily tasks through automation and gain visibility into their workflows.
What is Apache Airflow?
Apache Airflow is an open-source workflow management platform developed by the Apache Software Foundation that allows users to author, schedule and monitor workflows or pipelines. At its core, Airflow is a platform to programmatically author pipelines as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler takes care of dynamically triggering and monitoring tasks in the pipeline based on their schedule, dependencies, and execution parameters.
Some key features of Apache Airflow include:
- Visualizing pipelines as DAGs
- Easy to use Python-based APIs to author workflows
- Robust scheduling and dependency resolution
- Monitoring and alerting on tasks and DAGs
- Ad-hoc task execution for debugging
- Large community and ecosystem of plug-ins
Apache Airflow was initially created at Airbnb in 2015 to address the need for a workflows and data pipelines platform for scheduling ETL, data engineering, and machine learning workflows. Since then, it has become one of the most widely used open-source platforms for data orchestration.
Why Use Apache Airflow for Data Engineering?
There are several reasons why Apache in data engineering has become indispensable for data engineers:
- Scheduling: Airflow allows the scheduling of workflows and tasks using cron expressions. This ensures data pipelines and processes run automatically on a defined schedule without manual intervention.
- Monitoring: The Airflow UI provides a real-time view of pipeline status along with task details. It enables quick troubleshooting of failures without digging through logs.
- Dependency Management: Airflow resolves dependencies between tasks in a DAG automatically based on upstream and downstream relationships. This prevents issues from incomplete or invalid data.
- Reusability: Operators can be reused across DAGs, promoting code reuse. This reduces the development and maintenance costs of pipelines over time.
- Scalability: As data volumes increase, Airflow pipelines can be designed to scale horizontally by distributing tasks across multiple workers.
- Visibility: The user-friendly interface provides visibility into complex workflows and their relationships for documentation and auditing purposes.
- Extensibility: Being open-source, Airflow has a huge ecosystem of plug-ins and community support to extend its capabilities for new frameworks, data stores or environments.
So in summary, by using Airflow data engineers can develop complex and robust data workflows with increased visibility, reliability and maintainability.
Getting Started with Apache Airflow
Here are the basic steps to getting started with Apache Airflow for developing data pipelines.
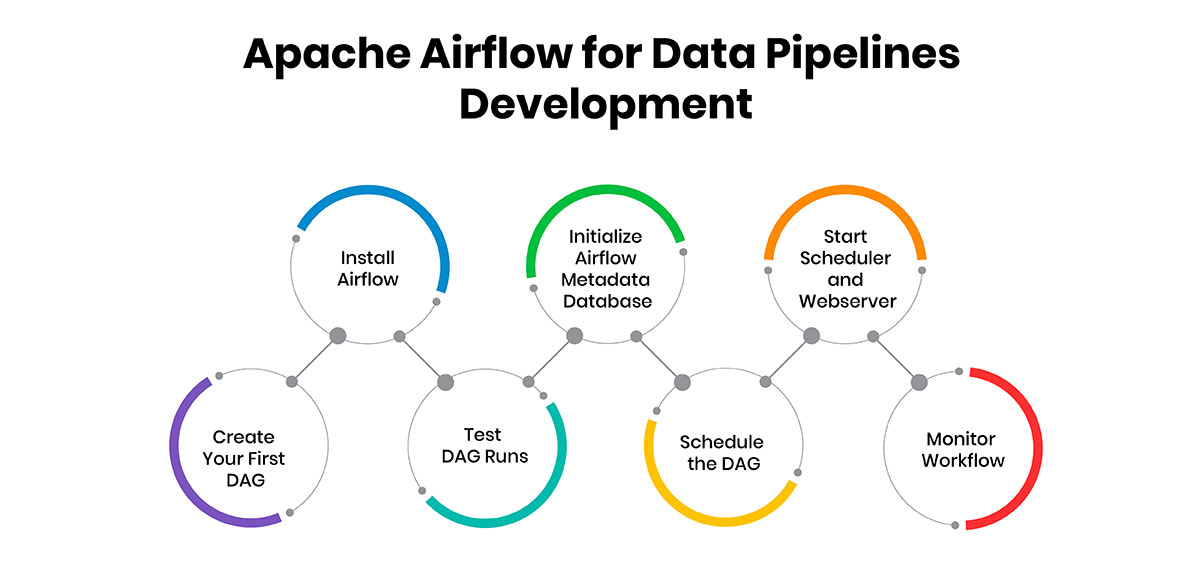
1. Install Airflow
Airflow can be installed via pip on major platforms, as well as via Docker. With pip, you need Python and a database backend like PostgreSQL, MySQL, or SQLite.
To install via pip:
-
Ensure you have Python 3.6 or later installed. You can check your Python version using:
python3 --version
- Install pip if it's not already installed.
-
Create a virtual environment and activate it:
python3 -m venv airflow_env
source airflow_env/bin/activate -
Install Apache Airflow and its dependencies:
pip install apache-airflow
Alternatively, to install via Docker:
Docker provides an easy way to deploy Airflow without worrying about dependencies.
-
Pull the official Docker image:
docker pull apache/airflow
-
Run the Airflow container:
docker run -d -p 8080:8080 apache/airflow webserver
2. Initialize Airflow Metadata Database
Airflow stores metadata such as task states, DAGs, and configuration parameters in a dedicated database. It supports PostgreSQL, MySQL, SQLite, and other databases.
To initialize the metadata database, run the following command:
airflow db init
This will create the initial schema. You can specify the connection string for your database via environment variables or in the airflow.cfg file.
3. Start Scheduler and Webserver
The scheduler and webserver are long-running services that power the core functioning and UI of Airflow.
-
Start the scheduler:
The scheduler periodically triggers new DAG runs.airflow scheduler
-
Start the webserver:
The webserver runs the Flask application that powers the Airflow UI.airflow webserver
4. Create Your First DAG
A Directed Acyclic Graph (DAG) defines a workflow in Airflow. It is written as a Python script with tasks, operators, sensors, etc.
- Create a Python file named first_dag.py within the dags folder located in the AIRFLOW_HOME directory.
-
Import necessary modules and define tasks:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
# Default arguments
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 9, 1),
'retries': 1,
}# Define the DAG
dag = DAG(
'first_dag',
default_args=default_args,
description='A simple DAG',
schedule_interval='@daily',
)# Define the tasks
task_1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag,
)task_2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
dag=dag,
)# Set the task dependencies
task_1 >> task_2 - Save this DAG definition in the dags folder.
5. Test DAG Runs
To test the DAG:
-
Via the Airflow UI:
1. Go to the DAGs menu.
2. Select your DAG.
3. Click the "Trigger DAG" button to start a test run. -
Via the CLI:
airflow tasks test first_dag print_date 2024-09-02
This command tests the print_date task for the DAG first_dag on the specified date.
6. Schedule the DAG
By default, DAGs are not scheduled. To enable automatic periodic runs, set a cron schedule expression.
For example, in first_dag.py, the schedule_interval='@daily' argument schedules the DAG to run daily at midnight.
7. Monitor Workflow
From the Airflow UI:
- Monitor DAG runs in real-time.
- View task details, logs, and task status.
- Click on individual tasks to view their status and logs.
The UI provides a graphical view of task dependencies, color-coded task statuses, and the ability to trigger ad-hoc task runs. Logs are available to help diagnose and fix issues.
Example DAG with Conditional Task Execution
Here's an example of a more advanced DAG with conditional task execution:
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import BranchPythonOperator
from airflow.utils.dates import days_ago
from datetime import datetime
def choose_task():
return 'task_1' if datetime.now().second % 2 == 0 else 'task_2'
default_args = {
'owner': 'airflow',
'start_date': days_ago(1),
'retries': 1,
}
dag = DAG(
'conditional_dag',
default_args=default_args,
description='A DAG with conditional task execution',
schedule_interval='@daily',
)
branch_task = BranchPythonOperator(
task_id='branch_task',
python_callable=choose_task,
dag=dag,
)
task_1 = BashOperator(
task_id='task_1',
bash_command='echo "Task 1"',
dag=dag,
)
task_2 = BashOperator(
task_id='task_2',
bash_command='echo "Task 2"',
dag=dag,
)
branch_task >> [task_1, task_2]
This DAG will execute either task_1 or task_2 based on the current second value when the DAG runs.
With these steps, you can start developing, scheduling, and monitoring your data pipelines using Apache Airflow. Overall, the minimal learning curve and the Pythonic nature of DAG definitions make Airflow extremely approachable for any data engineer to build robust and scalable data pipelines.
Use Cases for Apache Airflow in a Data Engineering Team
Apache Airflow has become an integral part of day-to-day operations for many data engineering teams:
- ETL Workflows: Regular extract, transform and load processes as well as batch jobs.
- Data Ingestion: Streaming and batch ingestion into databases and data warehouses.
- Data Preparation: Tasks like validation, enrichment, profiling and schema changes.
- Machine Learning: Feature engineering, model training, evaluation, deployment, monitoring.
- Data Aggregation: Cron-based aggregation jobs for metrics, dashboards, analytics cubes etc.
- API ETL(Extract, Transform, Load): Data pulls/syncs from external API endpoints on a schedule.
- Testing: Regression and integration testing of pipelines during development and releases.
- Deployments: Deploying and replicating pipeline code across environments like dev/test/prod.
So, whether it’s regularly scheduled tasks or one-off ad-hoc jobs, Apache Airflow helps manage diverse data workflows for engineering teams with productivity and consistency.
Best Practices for Apache Airflow Deployments
Let's take a look at some of the best practices to consider when deploying and managing Airflow at scale:
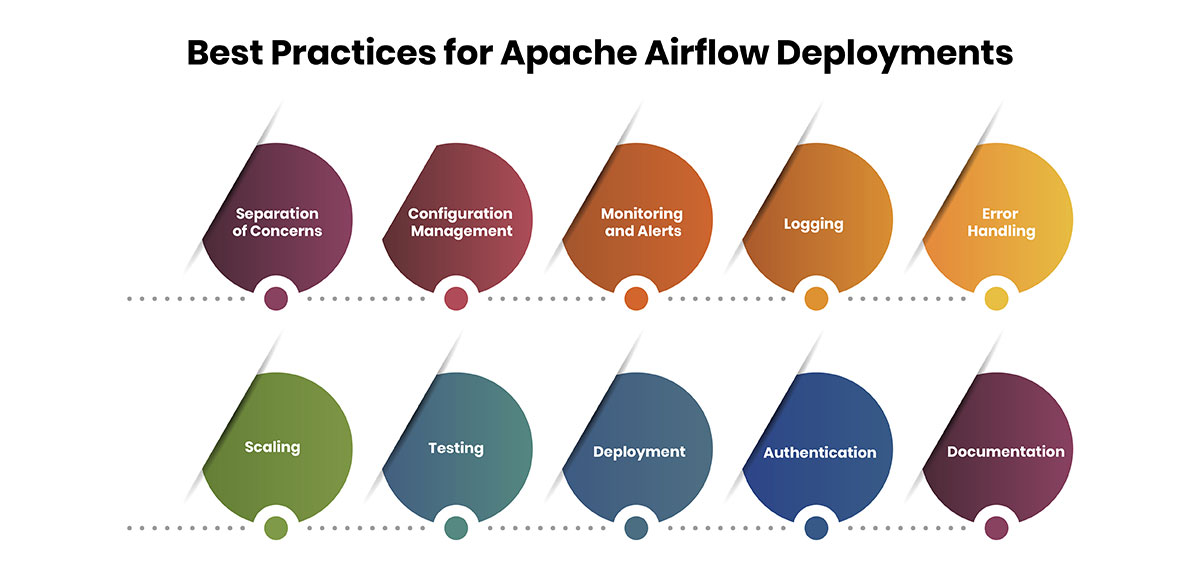
Separation of Concerns
As pipelines get developed by different teams or evolve over time, it is best to split code related to pipelines, configurations, plugins etc. across multiple code repositories. This allows for logical grouping and separation while making code management easier through compartmentalization.
For example, pipeline code can be maintained in one repository while configuration files, custom operators or hooks can live in separate repositories. Some teams even choose to organize repositories by line of business to further improve structure. This separation of concerns through proper code organization enhances maintainability, readability and collaboration between engineers.
Configuration Management
Keeping configuration details such as database connections, API keys etc. outside actual pipeline code is considered a security best practice. Storing configs in environment variables, config files, and secret management systems allows one to easily manage config access, rotate credentials and make upgrades without touching code.
This is generally done through a configuration management tool like Ansible which also aids in configuration audits. It is important that any sensitive information is well protected based on industry best practices for password policies and credential storage. Periodic configuration backups are also advised.
Monitoring and Alerts
To maintain operational visibility into Airflow workflows, it is important to implement monitoring of Kubernetes or EC2 resources as well as Airflow metrics. Tools like Grafana, Prometheus or CloudWatch can be used to collect CPU, memory, and disk metrics as well as Airflow-specific metrics like number of tasks succeeded/failed in the last 24 hours.
Setting up dashboards and alerts helps keep an eye on potential bottlenecks. For example, alerts can be configured for scheduler queue size increasing beyond normal thresholds indicating airflow workers may need to be scaled. Such monitoring enables engineering teams to address issues proactively before they impact pipelines.
Logging
Centralized logging brings immense value to debugging and auditing workflows. Tools like Elasticsearch Logging with Kibana (ELK stack) or CloudWatch Logs help aggregate logs from multiple sources into a searchable archive. This allows engineers to quickly investigate failures across schedulers, workers and pipelines for root cause analysis.
Correlating logs also aids in compliance as all activity gets captured in one place. The best practice is to send custom logs with additional context like task_id, dag_id etc. This makes debugging straightforward when downstream pipelines fail due to upstream dependencies. Regular log cleanup and retention policies should also be implemented.
Error Handling
Even with best testing practices, pipelines will inevitably fail occasionally in production. Thus, it is important to handle errors gracefully to avoid clogging up schedulers and workers. Features like configurable retries and alert policies help automate failure recovery.
Retry operations allow specified tasks to automatically rerun on transient errors instead of failing hard. This ensures pipelines can self-heal over time without manual intervention. Setting up failure alerts through email/chatops(Chat Operations) notifies engineers to review long-running failures.
One can also define "fallback" or " Plan B" tasks that get executed only when primary tasks fail to continue processing some data to the next stages instead of stopping the whole workflow. Proper error handling makes pipelines robust and self-servicing for scheduled runs.
Scaling
As workloads increase with more DAGs and tasks, Airflow deployments will need to scale resources over time to maintain performance. Vertical scaling involves adding more CPU/RAM to existing scheduler/worker nodes. Horizontal scaling distributes load by adding worker nodes that can process tasks in parallel.
Managed Apache Airflow on Kubernetes simplifies scaling operations since Kubernetes auto-scales pods based on metrics. It also enables features like canary deployments, blue/green upgrades and disaster recovery using cluster replication. Teams should monitor progression and autoscale resources elastically with their scaling policy to meet SLAs as load increases.
Testing
Testing is crucial to ensure the correctness and stability of production pipelines. Unit tests cover individual tasks or operators in isolation while integration tests validate inter-task dependencies. Setting up a proper testing framework boosts confidence before changes get deployed.
Parameters should be provided to DAGs for test runs and failing tests should fail builds. Parameterized tests also help reproduce issues quickly. Debug workflows like printing intermediate data or assertions within tasks assist with test validation. Regular testing of DAGs catches regressions early before impacting production data.
Deployment
To deploy newer pipeline versions reliably, teams should adopt continuous integration and continuous delivery practices. Standardizing deployment procedures, and validating YAML/JSON configurations are passed correctly, preventing toil and errors. Tools like Gitlab/Jenkins automate validation, linting and deployment of Airflow code/configurations.
Separating releases into feature flagging, and canary/validation runs before global rollout decreases the risk of failures impacting production data quality. Infrastructure as code with infrastructure templates also makes deployments repeatable and auditable. This brings confidence and agility in deploying pipeline changes without hampering operations.
Authentication
With Airflow handling sensitive pipelines, it becomes critical to lock down access at multiple levels. Authenticating users against metadata databases ensures that only authorized persons can view/edit pipelines. Limiting DB access through network policies/firewall rules secures this surface further.
Implementing role-based access control provides granular control of what users can do - view logs, trigger tasks etc. Airflow's built-in LDAP/OAuth integration simplifies identity management. Additionally, securing API credentials used by tasks prevents the leakage of secrets. Secure access provides assurance of data privacy and regulatory compliance.
Documentation
Every pipeline needs detailed documentation describing its purpose, data flows, upstream/downstream system interactions and SLAs. This serves as a single source of truth for new members and aids in understanding complex workflows. Standardizing pipeline specification templates ensures consistency.
Keeping documents updated concurrently avoids diverging assumptions. Storing documentation near pipeline code (eg. README, docstrings) serves as a self-contained reference. Overall, documentation brings transparency and knowledge reusability when engineering teams change over time.
Adopting these operational best practices for Apache Airflow ensures high reliability, scalability and manageability of pipelines in production environments.
Conclusion
In conclusion, Apache Airflow has become one of the most popular data engineering tools used widely in data engineering domains. As data engineering processes are increasing in organizations with varying data sources and data products, Apache Airflow plays an important role as it efficiently orchestrates tasks to build robust and scalable data pipelines. Overall, getting started with Apache Airflow provides data engineers with an integrated platform to automate their ETL processes to extract valuable insights from data. With its active community and cloud offerings, Apache Airflow continues to be a primary choice as a data engineering tool among organizations worldwide.













