


















In the land of DataBase Administrators (DBAs) struggling with NoSQL and Informatica Warehouses, the Big Data Engineer who can successfully architect, construct and govern an enterprise data lake, either on-premise or even better, in the public or hybrid cloud, is king. But a lake shouldn’t be a swamp, and the superlative big data engineer knows the difference. In an enterprise, structuring the ingestion, storage, cleansing and overall pre-processing of non-structured, non-relational data formats and then ensuring seamless transportation of the same to different teams and departments requires nothing less than a maverick team. But not everyone’s born a maverick, and learning the entire data lake concept, architecture and governance is a tall order unless you know the essentials of a data lake, and have the wherewithal to plan the architecture of one. Here’s a ground-up view of the mystical data repositories we call lakes, but are probably more akin to oceans.
What is a data lake?At its very essence, a data lake is data infrastructure that:
- Ingests, stores and processes all kinds of structured and unstructured data
- Maintains the different kinds of data in their native formats
- Allows the use of the data for on-demand analysis
- Allows the ingestion, storage, and processing to be done
- On premise
- On the cloud
- A hybrid of both
- Almost always in a centralized repository
- With a wide variety of file types
The importance of data lakes has grown significantly as well. A Forrester research report suggests that insight-driven businesses are growing 30% faster than their industry counterparts.
The need for data lakes in the big data eraThe massive amounts of data being generated in the Big data era called for the formation of data lakes. The erstwhile relational schema-on-write data warehouses and relational database management systems (RDBMSs) simply could not handle the variety, velocity and volume of data being generated and demanded by businesses. What was needed was a system that could continuously ingest data, store it, and offer real-time schema-on-read capabilities from a wide variety of data formats, for real-time processing and analysis. With the advent of Hadoop and NoSQL servers, data could be ingested and processed without increased pressure on computing resources.
The economics of the data lake cannot be overstated either! Bare-metal servers, collocated clouds and commodity hardware have made the storing of enterprise data a breeze.
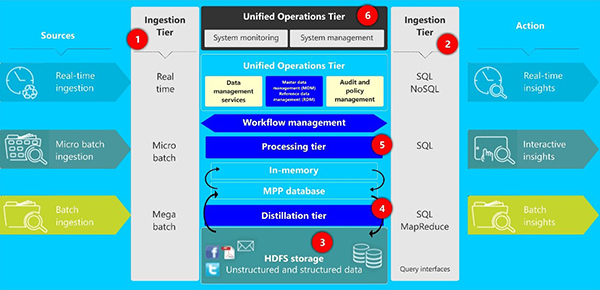
Data lake architectureThe architecture of a data lake includes several layers. Typically, the following are the components, in sequence of their functioning:
Ingestion - This refers to all forms of inputs into the data lake and usually contains commercial or open-source tools. Examples include Apache Kafka, Cloudera Morphlines and Amazon Kinesis. The most important aspect to keep at the forefront of your choice is the elasticity of the ingestion tool, and its ability to ingest streaming data.
Storage - This essentially is the “lake” in the data lake. Storage is not structured and files are in native formats, incorporating massively parallel processing (MPP). These include NoSQL databases that can be housed in commodity hardware, extremely cost-effective public or hybrid clouds, or even bare-metal servers in the enterprise’s own data center. The current trend is one of colocation and the use of hybrid clouds.
Data Preprocessing and Metadata - In the lake, metadata is maintained using several frameworks and tools. Metadata is used to identify and classify the data in the lake, and while it is not as structured as in a warehouse, it is certainly useful to acquire the correct data required for processing and modelling.
App Layer and Consumption - Once the data lake is prepared, the schema-on-read principle is used. The stored data is identified by the associated metadata and classification, and pulled out to the application layer for modelling or visualization, based on the needs of the enterprise. In most cases, these also happen in near real-time.
Data lakes are some of the most expensive insights-related storage projects undertaken by companies across the world, a fact corroborated by many industry experts. However, most such projects fail even while using famed service providers, because of the lack of understanding of the nature of data flow into and out of the data lake infrastructure. As the volume of business data keeps snowballing, more enterprises are seeking out skilled and certified Big Data Engineers for their Data Lake projects.














