


















In today's data-driven world, the term "big data" has become ubiquitous. From businesses and industries to academia and government, the concept of big data processing has permeated every facet of our lives. In this comprehensive big data guide, we will explore its nuances, benefits, challenges, and its vital role in various sectors. Whether you're a beginner or a seasoned professional in the big data arena, this guide will provide valuable insights and actionable tips to help you navigate this dynamic landscape.
What is Big Data: Introduction to Big Data
Big data refers to massive volumes of structured and unstructured data that cannot be effectively processed by traditional data processing tools. It encompasses data of all types, including text, images, videos, social media interactions, sensor data, and more. The key characteristics of big data, often referred to as the "3Vs," are volume, velocity, and variety.
Types of Big Data
Big Data is essentially classified into three types:
- Structured Data: This type of data is organized and follows a specific format, such as databases and spreadsheets.
- Unstructured Data: Unstructured data lacks a predefined structure, making it more challenging to analyze. Examples include social media posts and emails.
- Semi-Structured Data: This data type is partially organized and often contains metadata. XML and JSON files are common examples.
Benefits of Big Data
Understanding the benefits of big data is crucial for appreciating its significance. Here are some examples of how big data has transformed various industries:
- Healthcare: Big data analytics have enabled healthcare providers to enhance patient care, optimize treatment plans, and predict disease outbreaks.
- Retail: Retailers use big data to analyze customer behavior, improve inventory management, and personalize marketing campaigns.
- Finance: In the investment banking industry, big data aids in risk assessment, fraud detection, and algorithmic trading.
- Transportation: Big data helps optimize traffic management, reduce congestion, and improve the efficiency of public transportation systems.
- Manufacturing: Manufacturers use big data for predictive maintenance, ensuring machinery operates at peak efficiency and reducing downtime.
- Entertainment: Streaming platforms like Netflix utilize big data to recommend content based on user preferences.
5 Stages of Big Data Processing
Big Data Processing is a comprehensive journey that involves five distinct stages, each crucial in its own right. From the initial extraction of data to the application of machine learning, these stages pave the way for data-driven insights and informed decision-making. In this guide, we will delve into each stage, exploring their significance and the techniques involved.
Stage 1: Data Extraction
The foundation of Big Data Processing begins with data extraction. In this initial stage, data professionals gather information from a myriad of sources, including enterprise applications, web pages, sensors, marketing tools, and transactional records. This process spans both structured and unstructured data streams, and it is a critical step in building a comprehensive data warehouse.
One of the primary objectives during data extraction is to merge data from diverse sources and subsequently validate its accuracy by removing incorrect or redundant information. The data collected during this phase must not only be voluminous but also labeled and precise, as it forms the basis for future decision-making. Stage 1 establishes both a quantitative standard and a goal for improvement.
Stage 2: Data Transformation
Data transformation is the stage where raw data is refined into required formats, facilitating the generation of insights and visualizations. Several transformation techniques come into play, including aggregation, normalization, feature selection, binning, clustering, and concept hierarchy generation. These techniques are instrumental in converting unstructured data into structured data and further transforming structured data into formats that are readily comprehensible to users.
As a result of this transformation, both business and analytical operations become significantly more efficient. Organizations can make informed, data-driven decisions, leading to improved overall performance.
Stage 3: Data Loading
In the data loading stage, the transformed data is transported to a centralized database system. To optimize this process, it's essential to index the database and remove constraints beforehand, streamlining the efficiency of data loading. With the advent of Big Data ETL (Extract, Transform, Load) tools, the data loading process has become automated, well-defined, consistent, and adaptable to both batch-driven and real-time scenarios.
Stage 4: Data Visualization/BI Analytics
The fourth stage of Big Data Processing involves the utilization of data analytics tools and methods to visualize vast datasets and create informative dashboards. This visualization offers stakeholders a comprehensive overview of business operations. Business Intelligence (BI) Analytics plays a pivotal role in addressing fundamental questions related to business growth and strategy.
BI tools are capable of making predictions and conducting what-if analyses on transformed data, enabling stakeholders to discern intricate patterns and correlations among attributes. This stage empowers organizations to make data-driven decisions that can have a profound impact on their strategies and outcomes.
Stage 5: Machine Learning Application
The Machine Learning phase represents the pinnacle of Big Data Processing, focusing on the development of models that can adapt to new input. Learning algorithms enable the rapid analysis of vast amounts of data. Three primary types of Machine Learning techniques are employed:
- Supervised Learning: This method utilizes labeled data to train models and predict outcomes. Patterns in the data are used to identify new information output based on predefined labels. Supervised Learning is commonly employed in applications that leverage historical data to forecast future outcomes.
- Unsupervised Learning: In contrast, Unsupervised Learning operates on unlabeled data, with algorithms trained to identify patterns and relationships autonomously. This approach is valuable for scenarios where historical labels are absent.
- Reinforcement Learning:
In the final type, models make decisions autonomously based on observations and surrounding situations. These decisions are influenced by a reward function, encouraging the models to make optimal choices. Reinforcement Learning is particularly useful when primary data cannot be inserted directly into models.
The Machine Learning phase of Big Data Processing empowers automatic pattern recognition and feature extraction from complex, unstructured data, reducing the need for human intervention. This capability is a valuable resource for researchers and organizations engaged in Big Data analysis.
These five stages of Big Data Processing provide a structured framework for organizations to extract, transform, load, analyze, and derive meaningful insights from vast datasets. By mastering these stages and leveraging the power of Machine Learning, businesses can unlock the full potential of their data, gaining a competitive edge and making data-driven decisions that drive success.
Big Data Vs. Traditional Data
Big data differs significantly from traditional data in several aspects:
- Volume: Big data involves massive datasets, often too large to handle with traditional databases.
- Velocity: Big data is generated at an unprecedented speed, requiring real-time or near-real-time processing.
- Variety: Big data includes diverse data types, from structured to unstructured, which traditional databases struggle to manage.
- Value: Big data focuses on extracting actionable insights, whereas traditional data may prioritize transactional processing.
Steps of Big Data Processing
Big data processing is a complex but highly rewarding endeavor. To effectively harness the power of big data, it's essential to follow a structured process. Let’s look at each step, emphasizing their significance in ensuring data quality and extracting valuable insights:
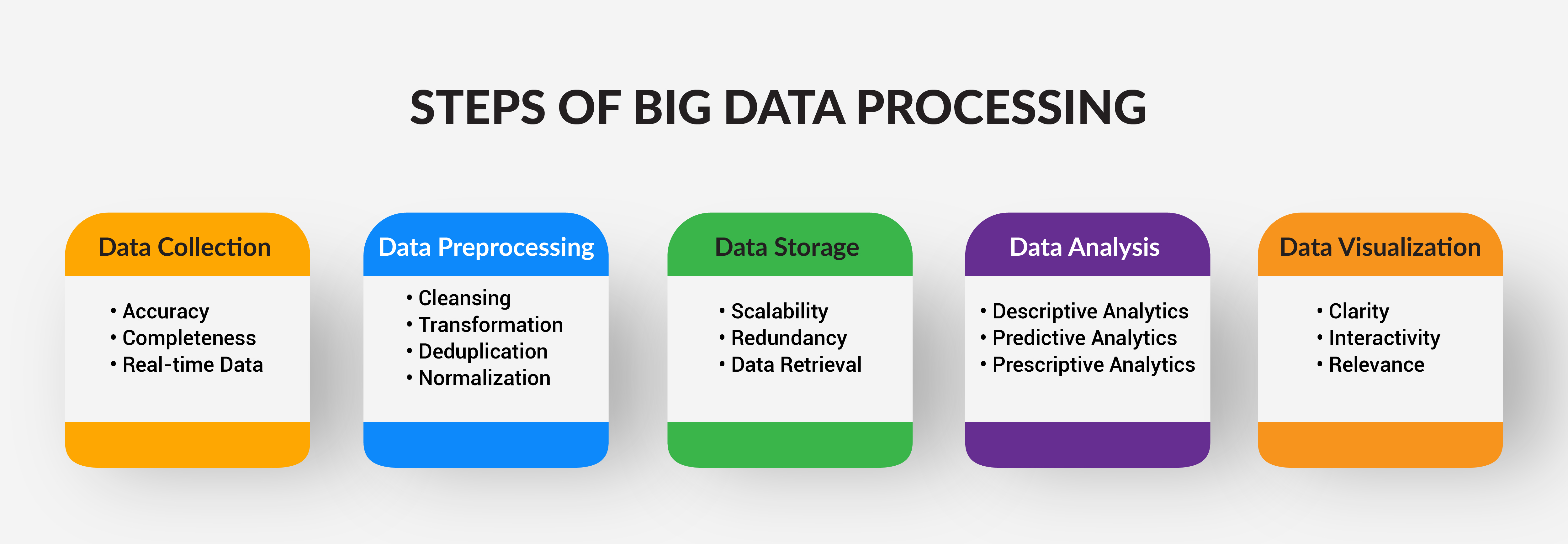
Data Collection
The first crucial step in big data processing is data collection. Here, the goal is to accumulate data from various sources, ranging from structured databases to unstructured sources like social media and IoT devices. For instance, in the investment banking industry, data can originate from financial transactions, market data feeds, news articles, and more. The key considerations during data collection are:
- Accuracy: Ensuring that the data collected is accurate and free from errors or omissions. Any inaccuracies at this stage can ripple through the entire processing pipeline, leading to flawed insights.
- Completeness: Gathering all relevant data is imperative. Missing pieces of the puzzle may result in incomplete analysis and inaccurate conclusions rely on comprehensive data for risk assessment and decision-making.
- Real-time Data: In some scenarios, real-time or near-real-time data collection is essential. This is especially true in trading environments, where up-to-the-minute information is critical for making investment decisions.
Data Preprocessing
Once data is collected, it rarely arrives in a pristine, ready-to-analyze state. Data preprocessing involves several critical tasks to clean, transform, and prepare the data for analysis:
- Cleansing: This involves identifying and rectifying errors, such as missing values, outliers, and inconsistencies. In investment banking, data cleansing ensures that financial data is accurate, which is vital for modeling and predicting market trends.
- Transformation: Data often requires transformation to make it compatible with the analysis tools and techniques that will be used. This may include converting data types, scaling values, or aggregating data over specific time periods.
- Deduplication: Duplicate records can skew analysis results. Removing duplicate entries ensures that each piece of data contributes meaningfully to the analysis.
- Normalization: Scaling data to a standard range can help prevent the dominance of certain variables in statistical analysis, promoting fairness in decision-making.
Data Storage
The third step, data storage, is fundamental in the big data processing pipeline. It involves housing the prepared data in storage systems designed to handle large volumes of information efficiently. Key considerations in data storage include:
- Scalability: As data volumes grow, the storage system should be able to scale seamlessly to accommodate increasing amounts of data. In industries where vast amounts of historical data are essential for risk modeling, scalability is paramount.
- Redundancy: Ensuring data availability and integrity is critical. Implementing redundancy mechanisms like data replication and backup systems safeguards against data loss.
- Data Retrieval: Access to stored data should be fast and reliable. For example, In healthcare, quick access to historical medical data can make a difference in timely decision-making.
Data Analysis
The heart of big data processing lies in data analysis. In this step, professionals leverage advanced analytics tools and techniques to derive actionable insights from the prepared data. This stage is vital for assessment, optimization, and identifying opportunities. Key aspects of data analysis include:
- Descriptive Analytics: This involves summarizing and visualizing data to gain an understanding of its characteristics and trends. Tools like data dashboards and charts are commonly used for this purpose.
- Predictive Analytics: Predictive modeling and machine learning are employed to forecast future trends and outcomes. In sectors like healthcare and financial services, predictive analytics can aid in predicting market movements and assessing risk.
- Prescriptive Analytics: Prescriptive analytics provides recommendations for decision-making. Investment bankers can use this to optimize investment strategies and make informed decisions.
Data Visualization
The final step in the big data processing journey is data visualization. After deriving insights from the analysis, presenting the results in a comprehensible format is crucial for decision-makers. For instance, In investment banking, clear visualizations of financial data, risk assessments, and market trends facilitate effective communication and decision-making. Key considerations for data visualization include:
- Clarity: Visualizations should be clear and easy to understand, even for non-technical stakeholders.
- Interactivity: Interactive dashboards allow users to explore data further and gain deeper insights.
- Relevance: Ensure that the visualizations align with the objectives of the analysis and address the specific needs of the audience.
Effective big data processing is a multi-step journey, from collecting and preprocessing data to storing, analyzing, and visualizing it. In industries where data-driven is paramount, each of these steps plays a pivotal role in ensuring accurate risk assessments, informed decisions, and competitive advantages. By following these steps meticulously, professionals can unlock the full potential of big data and drive success in their careers.
Why is Big Data Important for Businesses?
Big data plays a pivotal role in modern business operations for several reasons:
- Informed Decision-Making: It enables data-driven decision-making, allowing businesses to make informed choices based on real-time insights.
- Competitive Advantage: Companies that harness big data gain a competitive edge by understanding customer behavior and market trends better.
- Improved Efficiency: Big data helps optimize operations, reduce costs, and enhance productivity.
- Innovation: It fosters innovation by identifying new opportunities and avenues for growth.
Challenges and New Possibilities in Big Data Processing
Big data offers immense potential and presents significant challenges:
Challenges
- Data Privacy: Managing sensitive data and complying with regulations is a constant challenge.
- Scalability: As data volumes grow, scaling up infrastructure becomes complex and costly.
- Data Quality: Ensuring data accuracy and quality is a continuous effort.
- Talent Shortage: There's a shortage of skilled big data professionals.
New Possibilities
- Edge Computing: Processing data closer to the source (the "edge") to reduce latency.
- AI Integration: Integrating artificial intelligence for advanced analytics.
- Blockchain for Data Security: Employing blockchain to enhance data security and transparency.
Conclusion
From healthcare to finance, big data processing has become an integral part of every industry that collects data and in today’s data driven world, there are hardly any industries that don’t. All of this does mean that the future is bright for professionals in big data. However, it’s important to understand the process while also being able to evaluate differences from traditional data. Big data, in its entirety, presents both challenges and possibilities, it is up to the big data professional to harness its power to make informed decisions, gain a competitive edge, and drive innovation.














